
Minimize side effects
Generating a random number, communicating over the network, or controlling a robot are all examples of side effects.
If the software can’t affect the external world, it is pointless. But unnecessary side effects can cause problems and better be avoided (see the previous post).
Advertisement for this post:
- Python-oriented with examples
- Visuals for side effect refactoring
- many links to other great posts and discussions
- it is NOT about functional programming
What are we striving for?
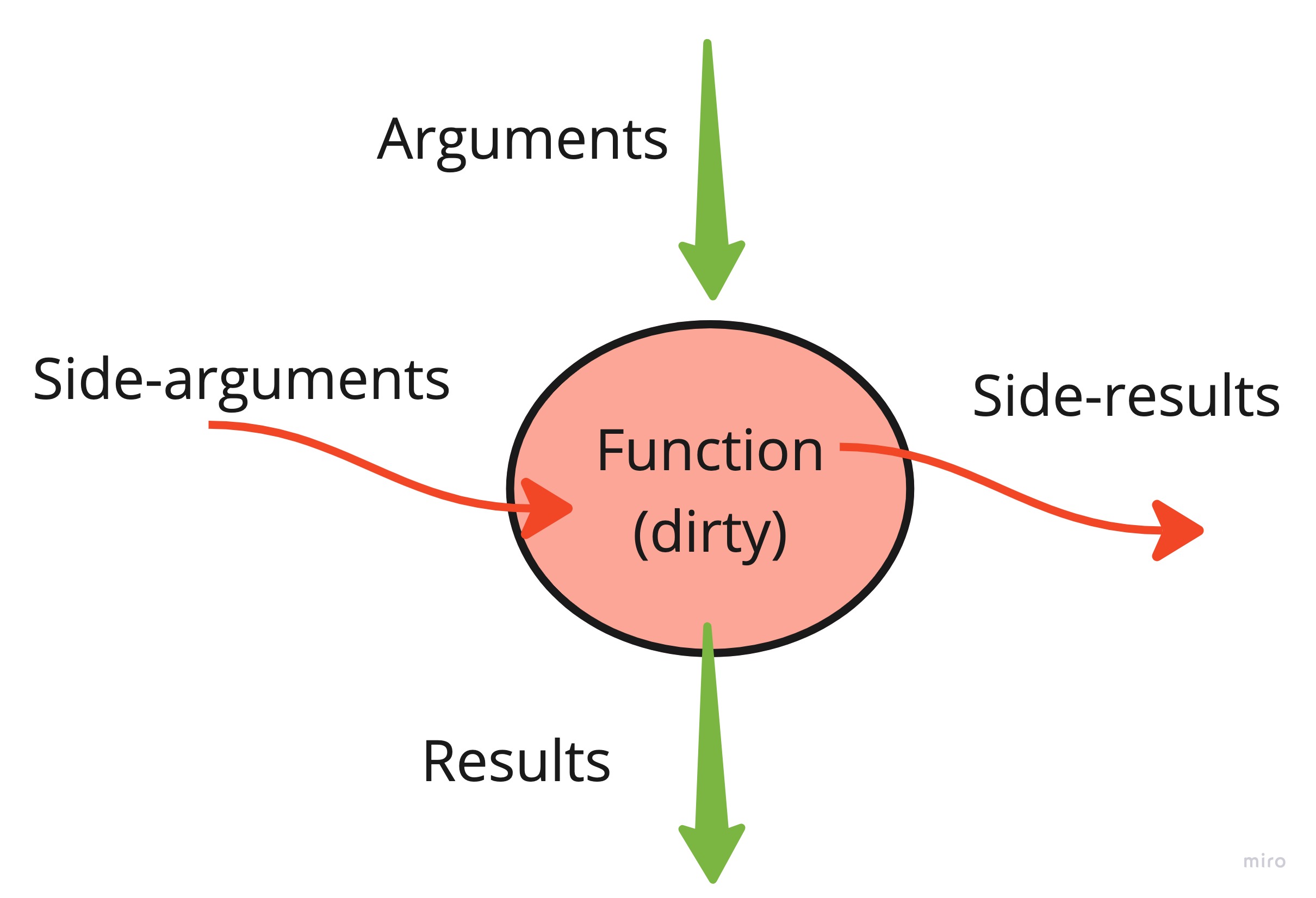
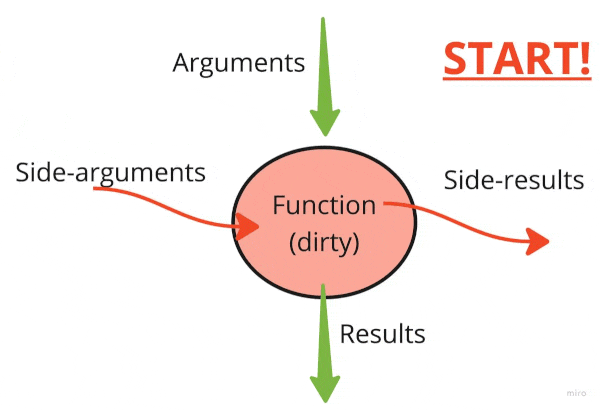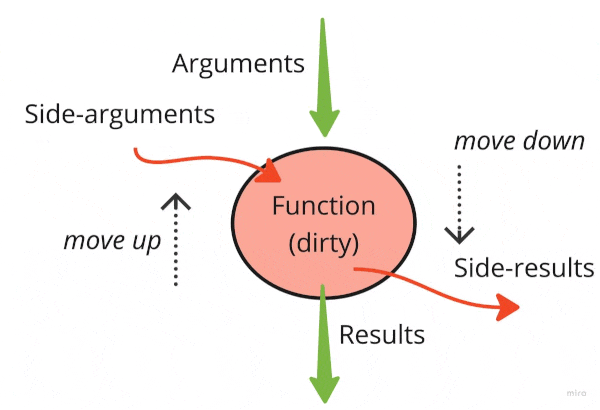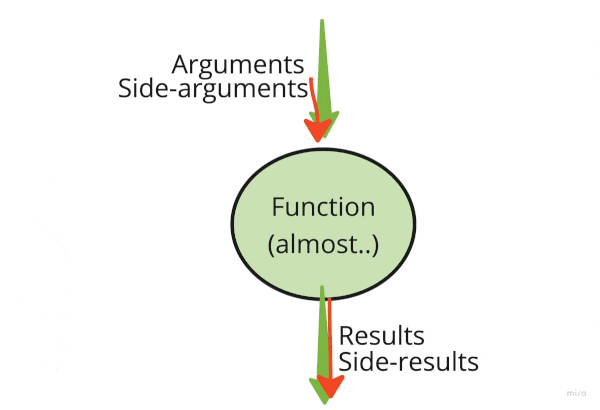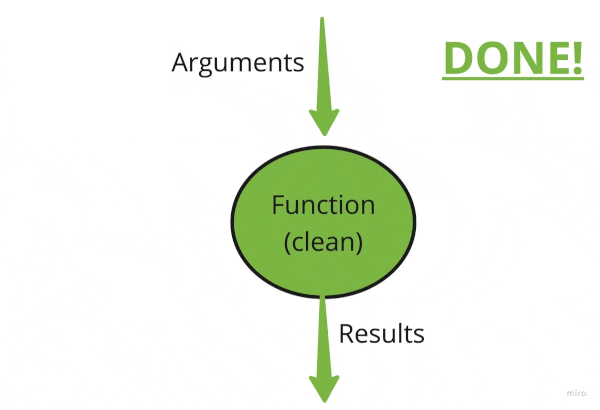
A good (“pure”) function should
- not cause any changes outside its scope (avoid side effects)
- produce the same output for the same set of inputs (avoid relying on hidden factors)
People debate whether the second property should be called a “side effect”. I will call incoming hidden factors “side arguments” and outgoing external side effects “side results.”
It seems like 65% of people are visual thinkers, so here are some pictures for you (the other 35% have to digest the code)!
| Dirty function | Example |
|---|---|
 | 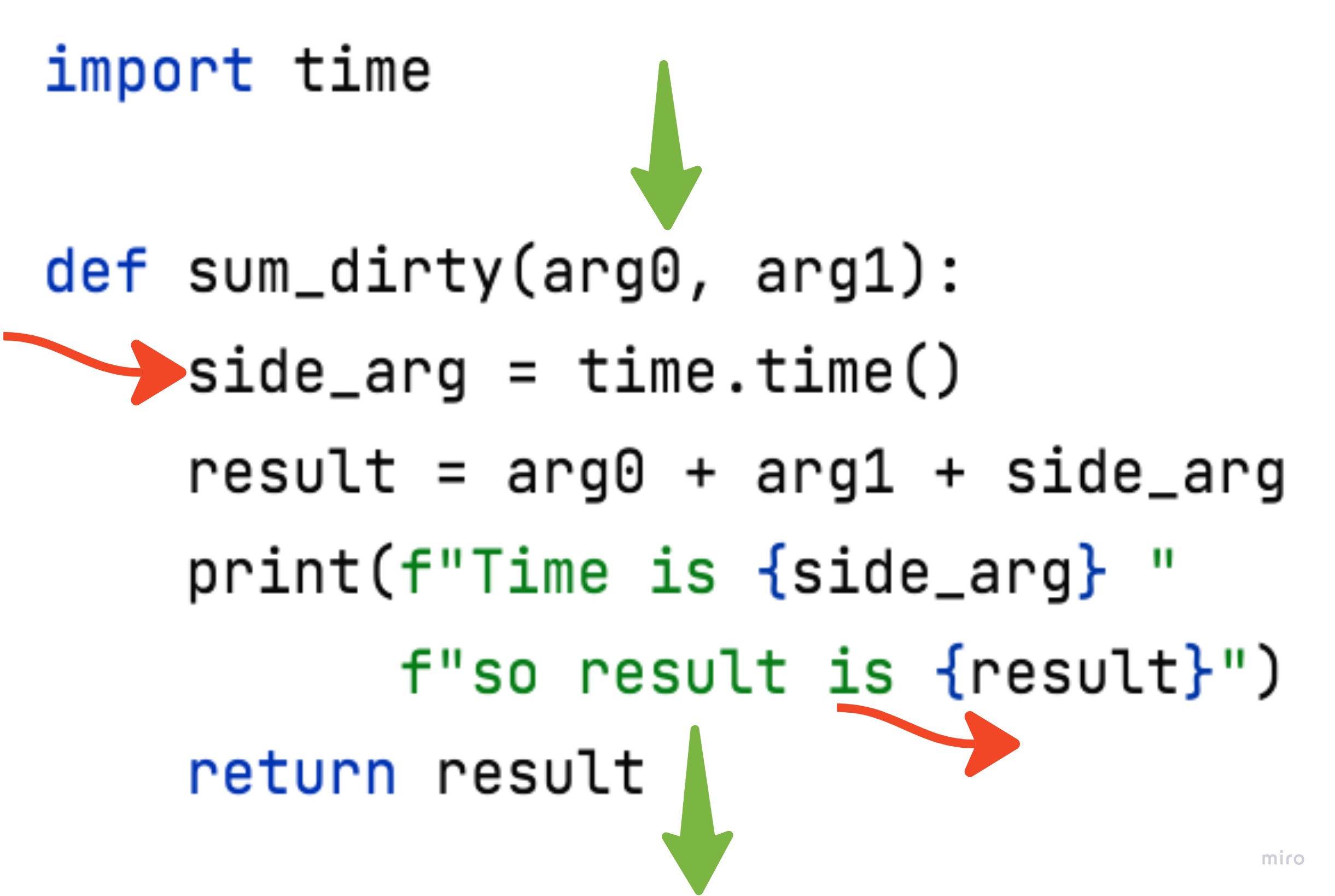 |
Calling system time.time() is an “input” side effect from the external system on the function.
The print statement is an “output” side effect from the function to the external world.
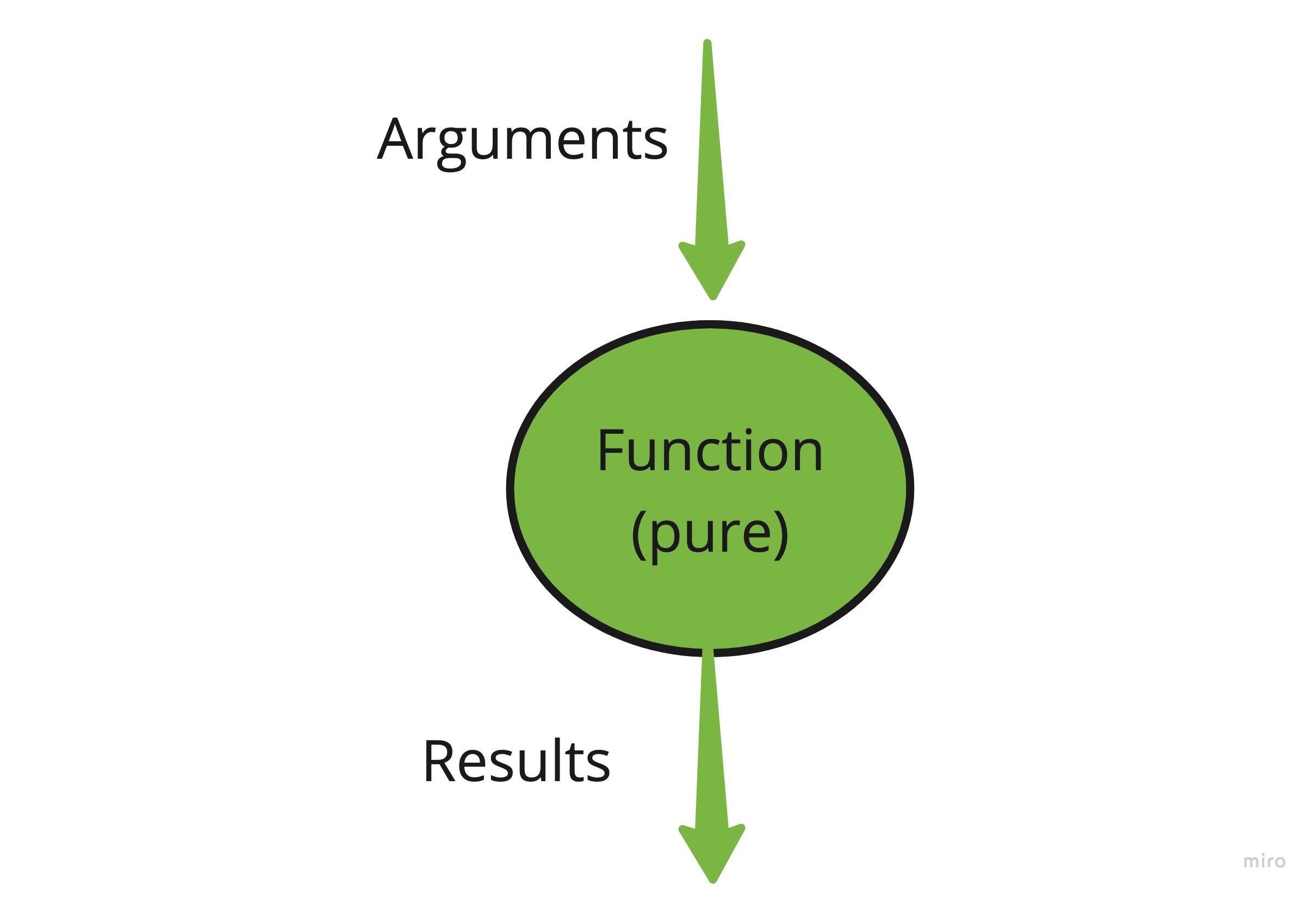
If one removes all side effects from this red “dirty” function,
we will get a side-effect-free green one:
| Clean function | Example |
|---|---|
 |  |
If you don’t bother cleaning up side effects your software will look something like this:
| Dirty application | Example |
|---|---|
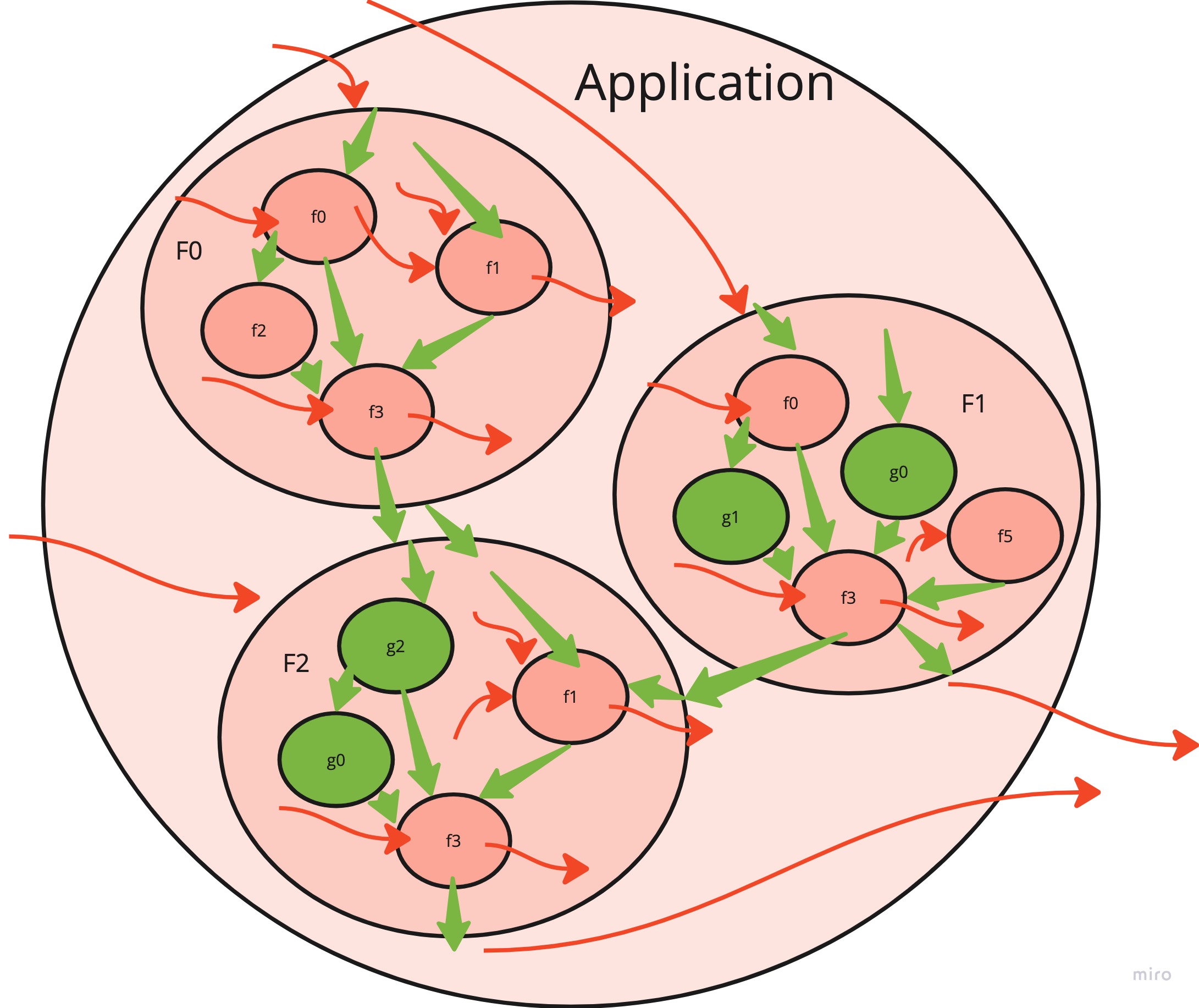 | 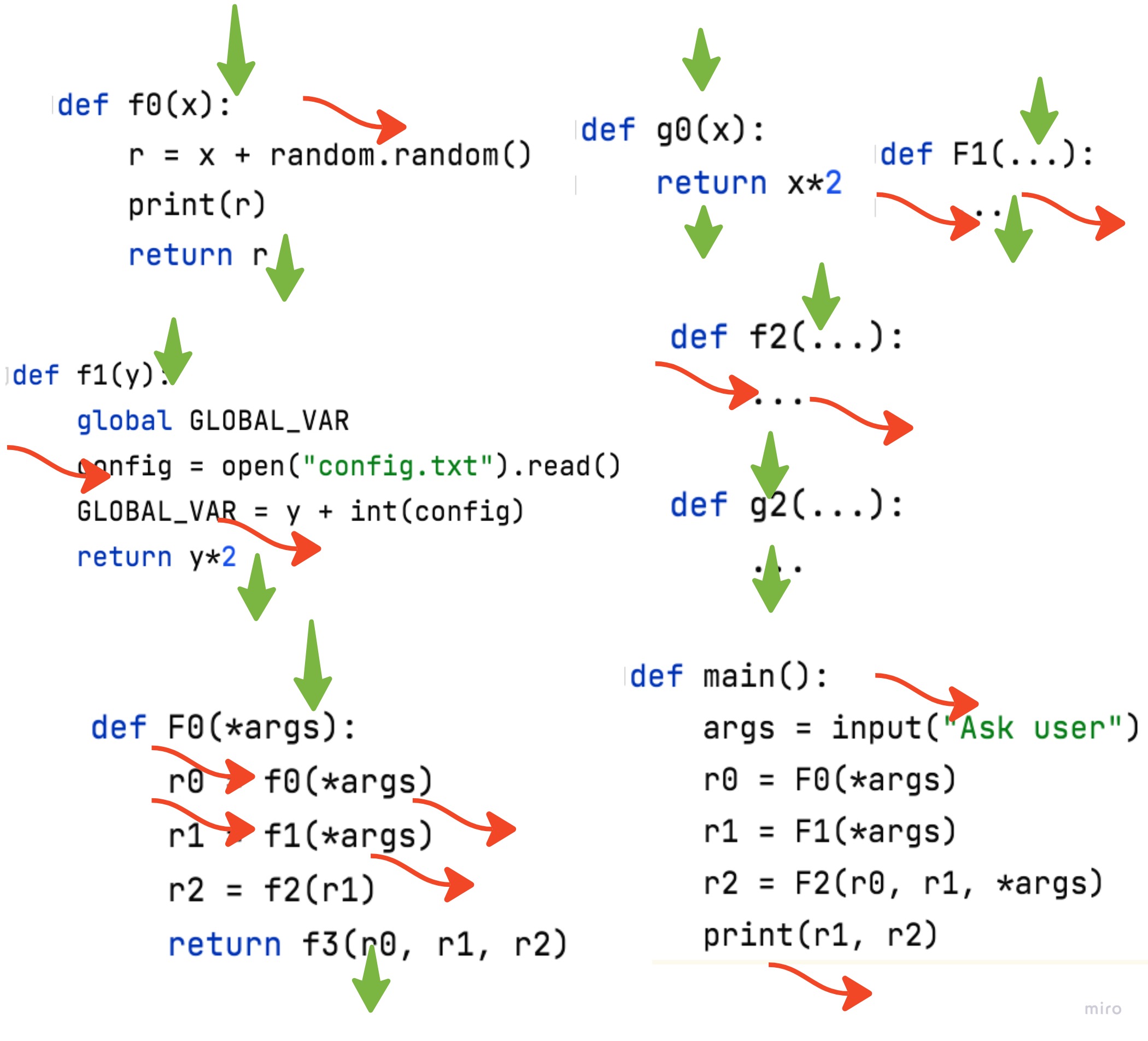 |
There are many dirty red functions called by top functions (larger circles). Both have side effects (side-arguments and side-results). Occasionally, a nice clean green function is buried underneath.
It’s important to understand what is the goal state here. We do not want to remove all side effects. Software that doesn’t interact with the world is truly useless. What we want to strive for is a picture like this:
| Clean application | Example |
|---|---|
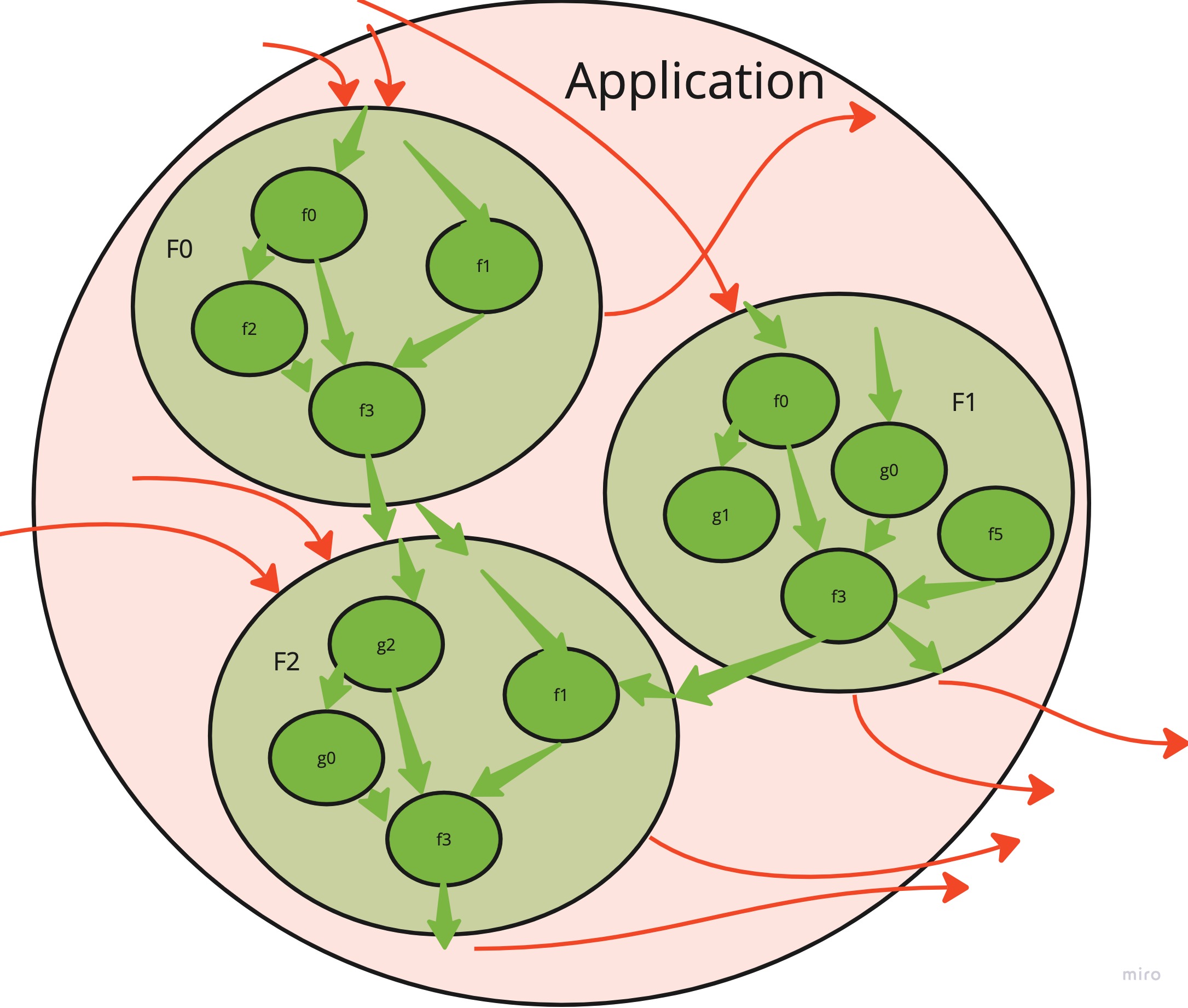 | 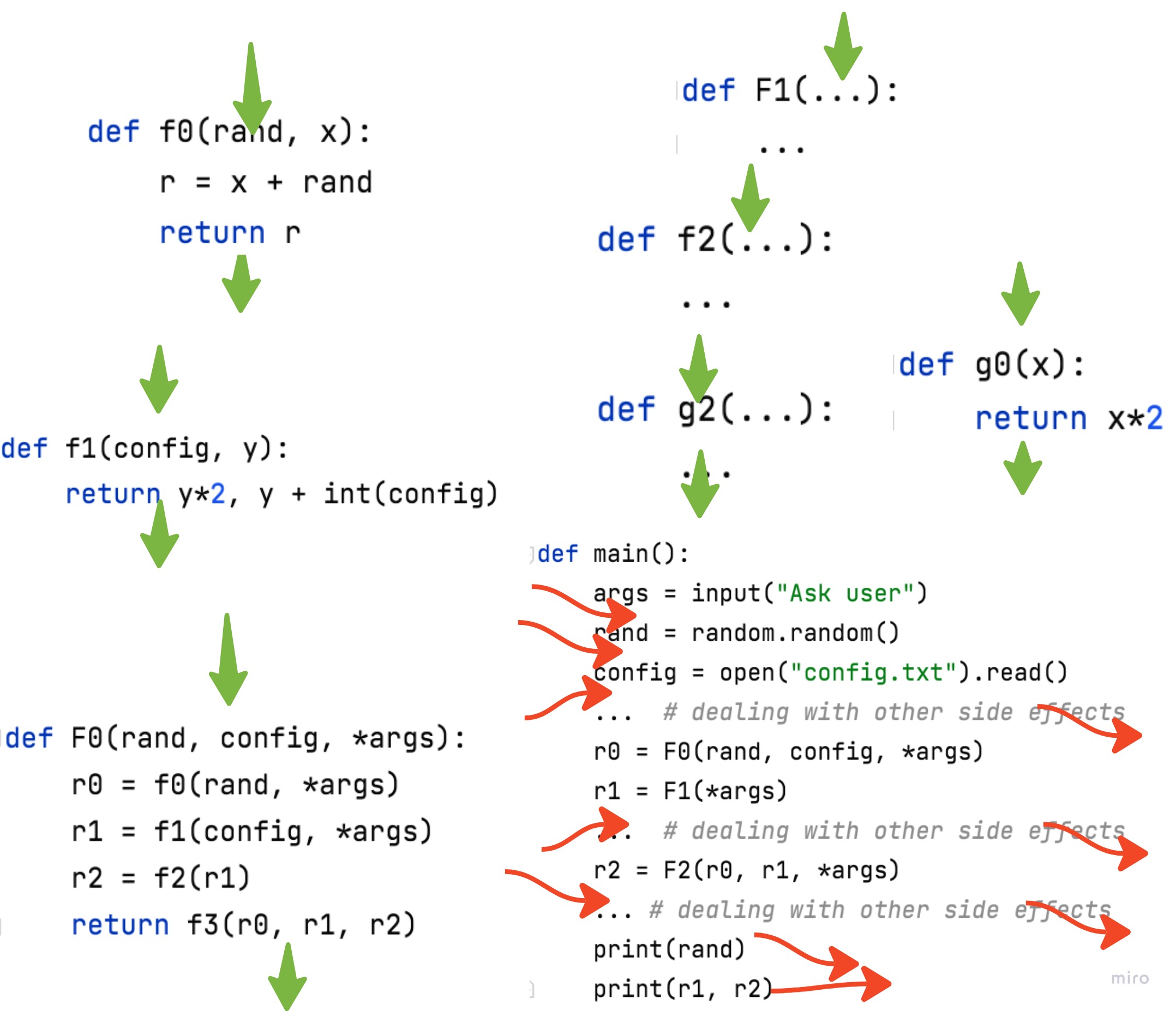 |
All necessary side effects are pushed to the application’s boundary, but all the internal core logic is green and clean! This is what’s called “Functional core, imperative shell”. There are at least a dozen posts I found about that idea. After digging around, it seems like this one is quite clean and has nice pictures. But also see this summary post and a discussion.
Start from the reusable utility function
Figuring out the correct order of refactoring can speed up the cleanup dramatically.
Notice that a dirty function down the stack infects all functions that call it. If there are ten-layer-deep function calls and a small utility at the bottom is dirty, the whole ten-layer stack is spoiled.
The first thing to do is to clean up frequently reused elementary functions and classes.
Hence, here is a good refactoring order:
- Identify highly reused dirty functions that are lowest in the call stack
- Clean them up (see below)
- Keep going until you run out of simple functions
- Move a level up the call stack
- Find reused dirty functions that are new lowest in the call stack
- …
- Strive for the “Functional core, Imperative shell” ideal!
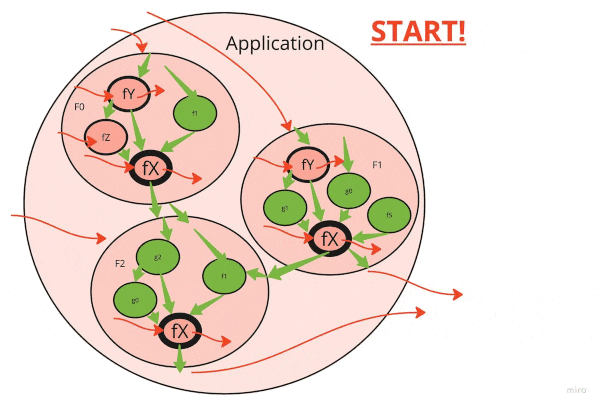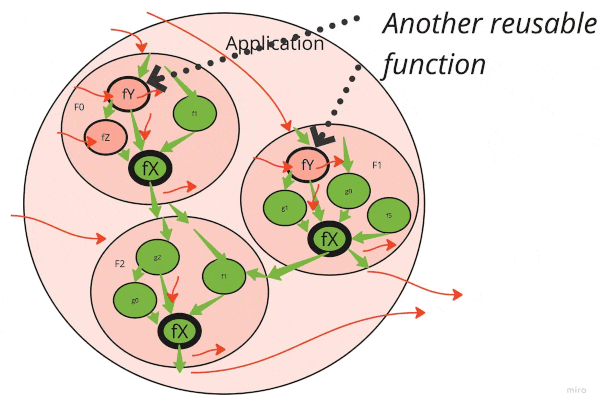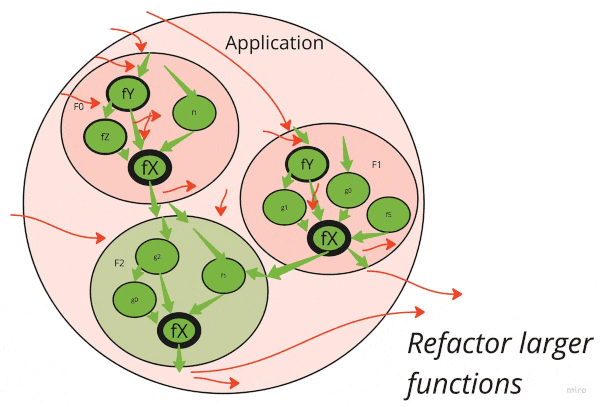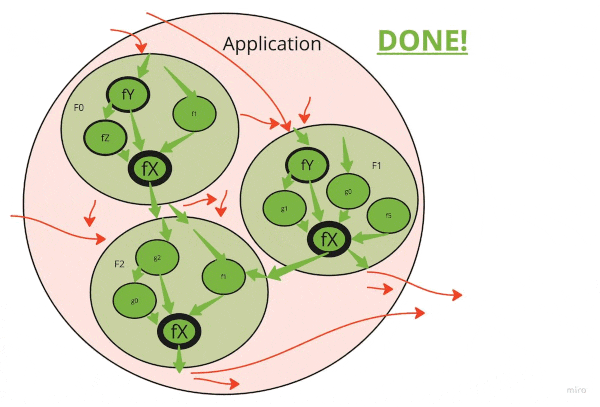
Remove some side effects altogether
Can you rewrite your function without affecting any external world whatsoever? That would be the best option! Sometimes neglected, but the first step is to remove unnecessary stuff. Here are some common examples.
Often, people think their logging statements will be helpful for others forever:
def inverse(x):
print("A message that I feel everyone"
"would benefit from!")
return -x
In reality, those logs are probably helpful just for you and only this week. A good rule of thumb is to remove most prints and logs from your branch before merging into the mainline. Most likely, you wouldn’t even notice the lack of a log message.
Another typical case is initializing an external resource for no reason. Quite often in machine learning, I see algorithms that create folders for saving results
def algorithm_1(x):
os.mkdir("folder_with_results")
return -x
It is not an algorithm’s job to create folders. Instead, it should be moved into the application initialization logic.
Sometimes people forget to remove a previously useful side effect after refactoring or debugging.
def algorithm(argument):
set_theano_flags(current_time=time.time()) # Init something used 5 years ago
result = (... complicated logic based on argument)
return result
To summarize, a decent percentage of side effects could be just removed completely.
Simple refactoring flow
What is the simplest refactoring recipe to make functions pure? Here is where the split on side arguments and results comes in handy:
- move side-arguments up the function body. Then transform it into a regular argument.
- move side-results down the function body. Then return the side effect together with other results. Some visuals for you:
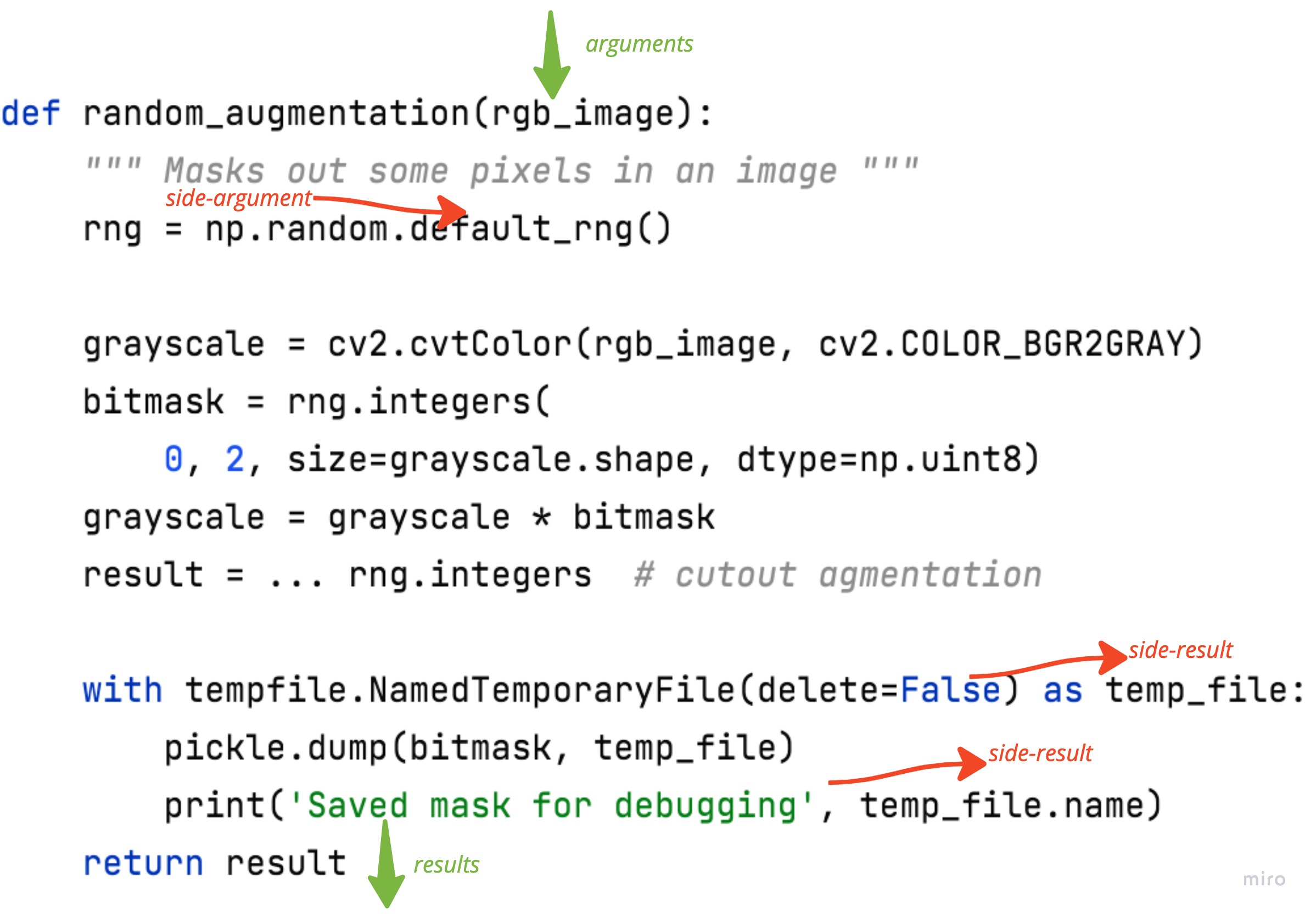
Let’s look at the real-life example I encountered. The following function performs some random image augmentations. The researcher sometimes wants to debug intermediate random masks and dumps them into temp files.
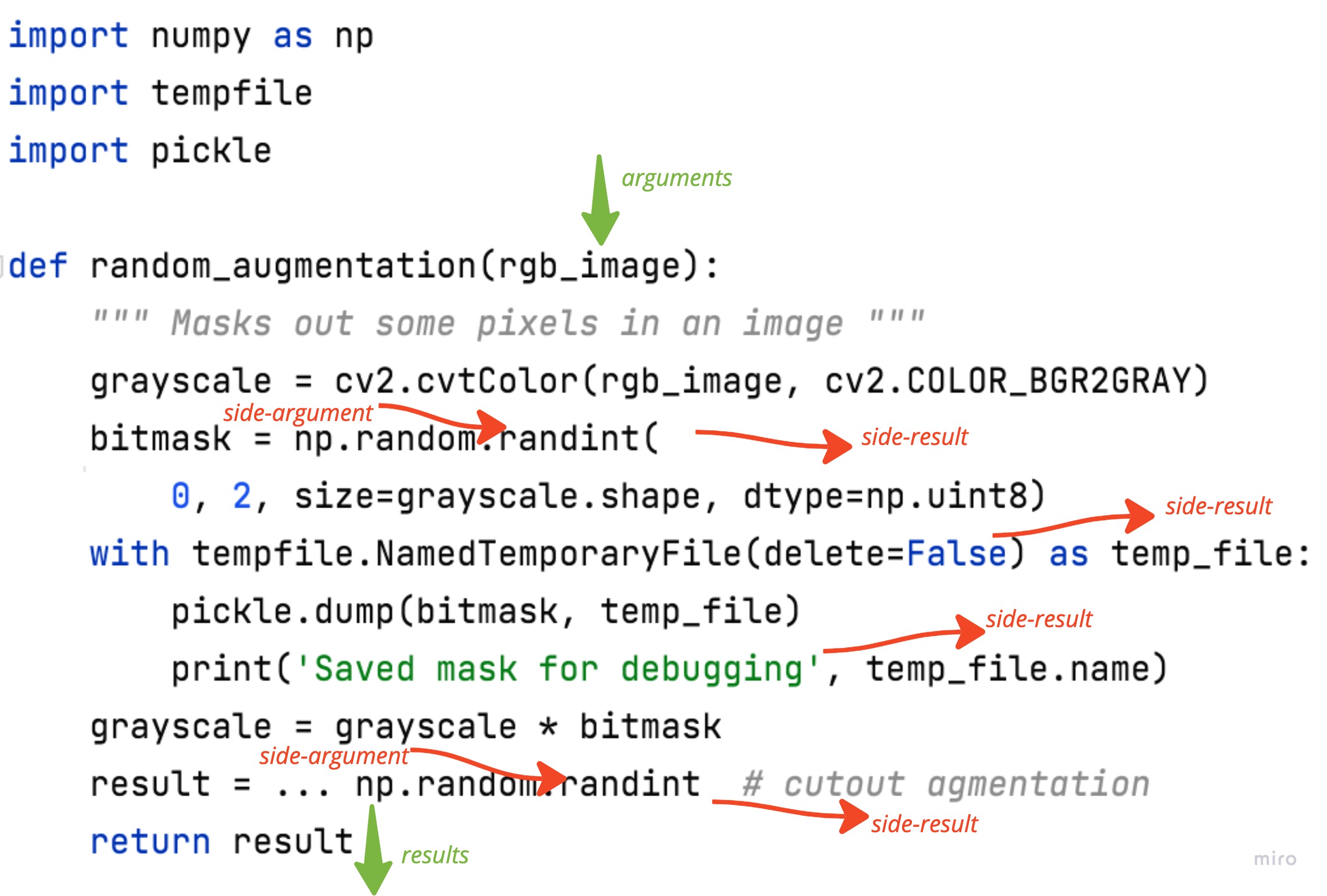
This function has 2 side-arguments: it reads from the global random generator for the random mask and a cutout. It has 4 side-results:
- change global random generator state 2 times
- writes a temp debug file
- prints out debug file name
This function is hard to test and will always bring you trouble by polluting /tmp and the console.
First, let’s move side-arguments up and side-results down. This step could be skipped, but I found it very useful in more convoluted and long functions. We create a random generator once from a global state and move debug outputs down:
Finally, let’s merge “side” and “regular” arguments and results. We arrive at a clean image augmentation logic:
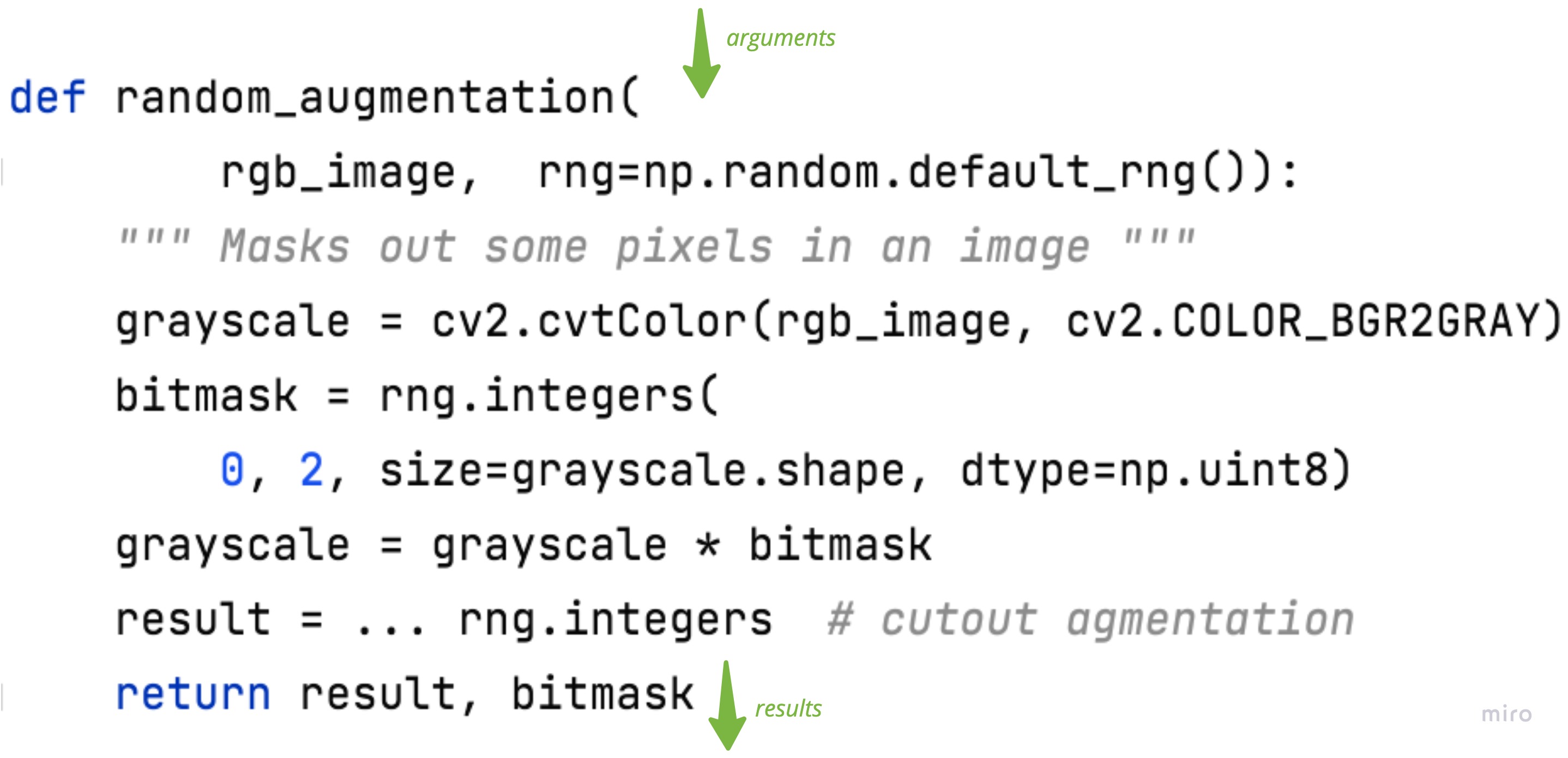
We are taking a random generator in and returning the debug mask.
The high-level function is free to choose whether to pass seeded rng for reproducibility or use the global one for convenience.
It will also decide how to save the debug masks if still needed.
Short-circuit side effects
Side-effects volume grows non-linearly. When one developer adds a side argument or a result, it encourages others to use a similar side channel.
When a function reads globals (envvars, files), it compels other functions to write to globals (envvars, files) so as to influence its behavior.
On the flip side, the more you remove, the easier it is to deal with the rest. After you move all side effects from the bottom up to upper functions, you typically find that you can completely “short-circuit” some. Here is a visual:
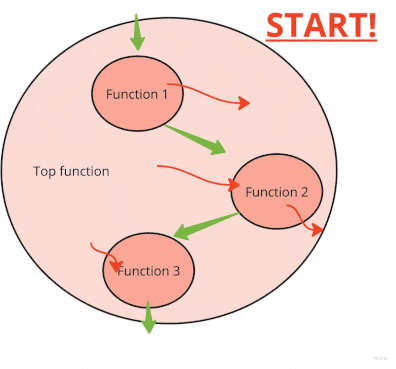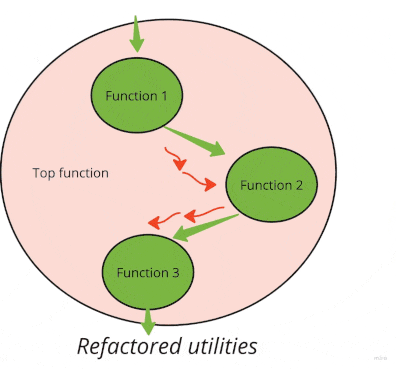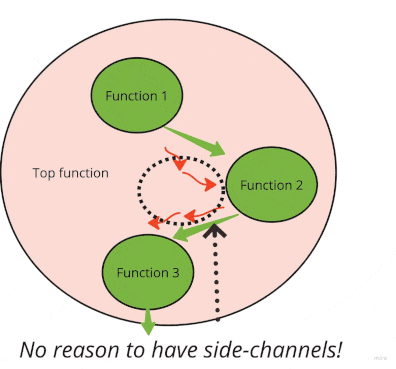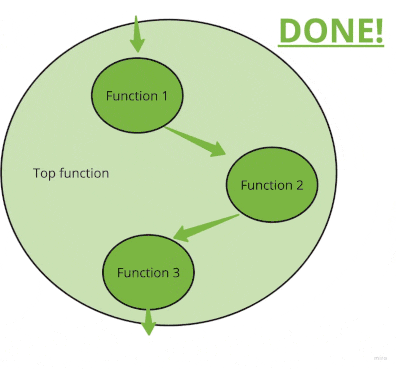
Let’s look at a real but a bit longer example. Here is an often-encountered pattern in research code to use the filesystem for passing parameters around:
- create a default config file ->
- modify the config file ->
- read out from a config file
Below is an extract from the actual code I encountered:
def dump_default_config(path):
default_config = {'hidden_size': 128, 'learning_coeff': 0.01}
with open(path, 'wb') as f:
pickle.dump(default_config, f)
def run_network(network_config_path, image):
with open(network_config_path, 'rb') as f:
config = pickle.load(f)
network = create_network(**config)
prediction = network(image)
return prediction
def network_main(image):
config_path = 'my_config.pkl'
dump_default_config(config_path)
# update the learning coefficient in the config file
with open(config_path, 'rb') as f:
config = pickle.load(f)
config['learning_coeff'] = 1e-4 # better learning coefficient
with open(config_path, 'wb') as f:
pickle.dump(config)
return run_network(config_path, image)Let’s move side arguments and results up the stack, as we discussed. First, move up the saving of the default config, and second, move up the config loading.
def create_default_config():
return {'hidden_size': 128, 'learning_coeff': 0.01}
def run_network(config, image):
network = create_network(**config)
prediction = network(image)
return prediction
def network_main(image):
config_path = 'my_config.pkl'
default_config = create_default_config()
with open(config_path, 'wb') as f:
pickle.dump(default_config, f)
# update learning coefficient in the config file
with open(config_path, 'rb') as f:
config = pickle.load(f)
config['learning_coeff'] = 1e-4 # better learning coefficient
with open(config_path, 'wb') as f:
pickle.dump(config)
with open(config_path, 'rb') as f:
config = pickle.load(f)
return run_network(config, image)Now we can short-circuit all the file system calls and arrive at neat, side-effect-free code. On top of being considerably smaller and simpler, it is also much faster:
def create_default_config():
return {'hidden_size': 128, 'learning_coeff': 0.01}
def run_network(config, image):
network = create_network(**config)
prediction = network(image)
return prediction
def network_main(image):
config = create_default_config()
config['learning_coeff'] = 1e-4 # better learning coefficient
return run_network(config, image)
To short-circuit a side effect, you should first identify input and output side effects of the same type (files, globals, envvars). Then you can lift all of them up the stack and remove them together.
Expose side effects to developers
Side effects might bring you problems, but hidden side effects are the worst. Imagine you decided to use an external library to make a friendly math-related application:
from external_library import compute_optimal_solution
def main():
x = input("Enter the number")
value = compute_optimal_solution(x)
print("Optimal value is :", exp(value))
You happily deploy it only to receive user complaints about database-related crashes.
You’re really surprised since you just wanted to provide some math utility and never intended to deal with databases.
Looking into the source of compute_optimal_solution, you might find something like:
def compute_optimal_solution(x):
result = 0
for i in range(1000):
result += i*x - log(i*x) + sin(i*x)
# to understand how people use our function,
# we log the results in the debug database
database_cache = sqlite3.connect(DEFAULT_DB)
cursor = database_cache.cursor()
cursor.execute(f"INSERT INTO MyDB (argument, solution) VALUES ({x}, {result})")
database_cache.commit()
cursor.close()
return result
You respect the developer’s desire to collect debugging data, but you would never have guessed it upfront. It would have saved you so much time if this function was named appropriately:
compute_optimal_solution_and_cache_solution_in_database(x)
You’d quickly realize that this function isn’t suitable for your basic math script.
It is a generic rule that the name of the function should describe what this function does. The same goes for side effects - if your function has a side effect, you better put it in its name. Using this naming rule, you’ll find that the ugliest and the most dangerous functions have the longest names! A long name indicates the need to refactor the function.
You also can expose side effects by splitting “clean” and “dirty” code on the module level.
For example, a library-like folder should have only clean side-effect-free code.
All side effects should go into an application-like folder (e.g., scripts, app, or runners).
Here is another nice short post reinforcing this point.
Misc and advanced
The points above should work for the majority of side-effect cleanups. But there are many exceptions and advanced concepts that wouldn’t fit this post. Here are some follow-ups.
Dependency injection? Injecting an object that might produce a side effect instead of producing it yourself is a common way to kick a can down the road:
- pass random generator instead of querying it
- pass
Timerinstead oftime.time() - pass
logging.Loggerinstead of aprint
After reading many resources, this thread is probably stays the best. Here is a great JavaScript post about it and side effects. In a liberal interpretation, replacing a side-argument by a regular one could be called a dependency injection. One should be careful not to overdo it (1, 2).
Return a functor? Instead of causing a side effect right away, you can return a “lazy” function that would do it later. See the post about this technique. Also, see “Lazy functions” section in this post. It’s a fun long read, but it probably goes beyond the needs of a regular Python mortal.
Copy an input container?
Modifying an incoming list or dict is also a side effect.
Quite often, it’s worth copying, modifying and returning it instead.
See the discussion here and this post.
Is it slower? Probably, yes. But the actual question should be this:
will your company spend more money on (A) executing slower code or (B) debugging bugs caused by side-effects?
Without picking (A) or (B), there is no basis for fear of slow but robust code.
prints and loggers?
While logging is a side effect, it’s not the worst one.
At least, the majority of developers don’t treat it as such.
It’s hard to advise anything specific without going on a long tangent.
You can adopt configurable logging, pass a logger as a dependency to every function, return string messages or stick with a print (e.g. if you use multiprocessing).
Conclusion:
At the end of the day, remember to be pragmatic: you don’t want to remove all side effects, you just want to remove unnecessary ones. In practice though, the majority of side effects are unnecessary. So you better allocate some time for refactoring and deal with them using some recipes from this post:
- make a pass on your code and remove some side effects altogether
- identify side-arguments and side-results and merge them with arguments or results
- identify reused utilities and clean them up first
- notice that some side-effects are caused by each other and short-circuit them
- expose side effects to developers.
Thank you for reading!