
I worked in research all my life, so I know a stereotype that researchers write ugly code (e.g. see here, here, or here). But I thought: we can fix it, right? So multiple times I tried to design nice research frameworks. I tried to bring in interfaces and create nice abstractions using software engineering books and blogs I liked reading.
But over and over again all those efforts went in vain. The majority of research software I worked on never went to production (although some did). It would have been great for my mental health if someone told me a simple truth: dying research code is actually what is supposed to happen. Researchers should not spend much time engineering it in the first place.
Professional software engineers always look down on researchers who are not using the best software practices. There are several posts trying to raise the bar of research code (e.g. this great post and a research code handbook). But this post goes other way around: it argues how to not overdo the best software practices and instead invest only in fast exploration. It is targeted for research-oriented companies where your goal is to try out many ideas fast.
1. Take on some strategic tech debt
A successful research project at a company has two phases: exploration and exploitation. In “exploration” you want to try out as many diverse solutions as you can. During “exploitation” you have to robustify the best solution and turn it into a useful product.
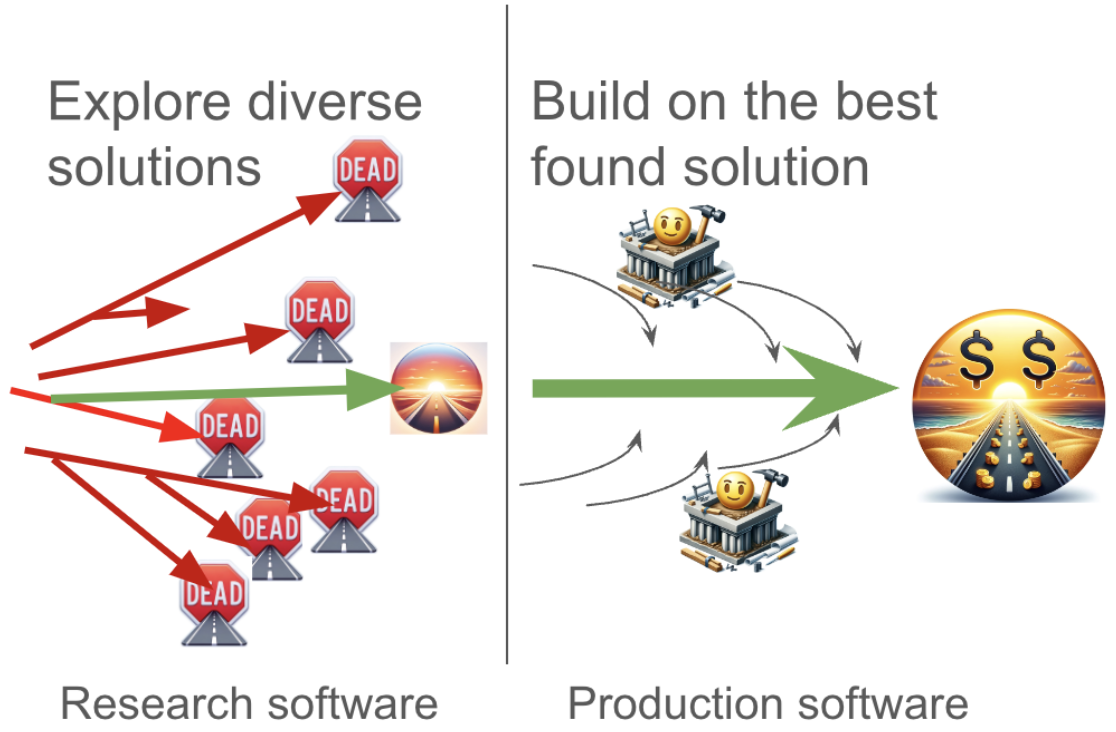
Optimal software practices are quite different between the two. That’s why companies often have separate research and product divisions. All the books you might typically read on software design are mainly about the second “exploitation” phase. In this phase you are building foundations for a scalable product. This is where all the design patterns come in: nice APIs, logging, error handling and so on.
But in the first “exploration” phase you are not building foundations that will live forever. In fact, if the majority of your efforts survive, then you (by definition) did not explore enough.
Many practices in this post are examples of what would normally become “tech debt”. It’s what you get by not writing clean reusable well-abstracted code. Is debt always bad? We prefer never getting a loan or a mortgage, but borrowing money is often a good strategy in life. It’s ok to get into debt to move fast and profit later.
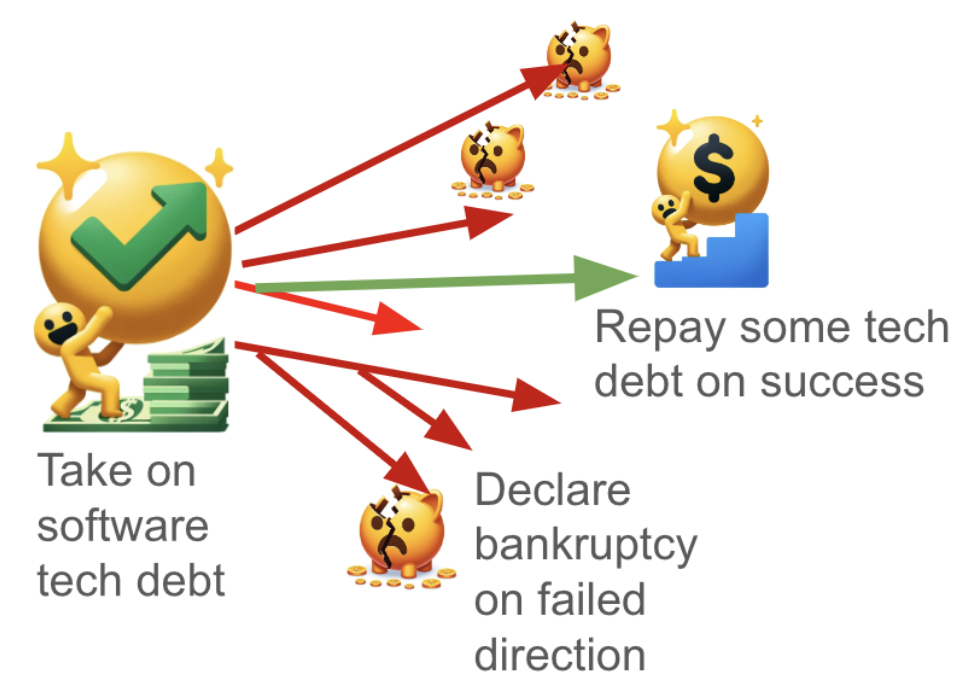
Similarly, by not taking technical debt you might be slowing down your research. The good news is that the majority of the time you don’t have to pay it back. Most of your research code is likely to die anyway. So on average, you will not be suffering from the whole tech debt you’ve taken.
The case against code reuse
Many software architectures and refactoring techniques are specifically oriented to improve code reusability. There are generic downsides to code reuse. But in production they are outweighed by the well-known benefits (for example, see this typical post). In research projects, the majority of the code is destined to sink to oblivion. Striving for code reuse could actually slow you down.
Limiting code reuse is the type of technical debt that is ok to take in research. There are several patterns of code reuse I want to discuss: adding an unneeded dependency, copypasting code, maintaining a lot of shared research code, premature design investments.
Think twice before importing something new
If you know a well-maintained versioned library that is going to speed you up - go for it! But before taking in a new dependency, try to make a judgment call whether it’s worth it. Every additional one brings you closer to dependency hell. It makes you invest time into learning and troubleshooting it. See more pitfalls of dependencies in this concise post.
It’s probably fine to depend on something if:
- you used it already, there is not much to learn, it has a large community, good docs and tests
- it is versioned, easy to install
- and finally, there is no way you can implement it yourself.
But be wary about a dependency if:
- you can’t figure out how to use it quickly, it is very new (or very old) or no one seems to know about it; there are no docs or tests
- it is from your monorepo and is constantly being changed by other teams
- it pulls in many other dependencies and tools; or it’s just hard to install
- and finally, you feel that you (or some LLM) can write this code in a few hours.
Instead of an explicit dependency, you can follow a nice Go proverb: “a little copying is better than a little dependency", which is our next topic.
Copypaste gives you freedom of experimentation

Some say that “copy-paste should be illegal”. But to my surprise I found myself arguing in favor of it quite often. Copypaste could be the optimal choice during the exploration phase.
If you depend on a heavily-used function from another part of the codebase you can forget about easily changing it. You’re likely to break something for someone and have to spend precious time in code reviews and fixes. But if you copypaste the necessary code into your folder, you are free to do anything you want with it. This is a big deal in research projects where experimentation is a norm rather than an exception. Especially if you are not sure if changes are going to be useful for everyone.
I find that deep learning codebases are suitable for copypasting the most. Typically, the amount of code needed to describe a model and its training is not so huge. But at the same it could be very nuanced and hard to generalize. Shareable training scripts tend to grow to an unmanageable size: e.g. Hugging Face transformers Trainer has +4k lines. Interestingly enough, transformers opted for copypaste on the model level. Please check out their post with the reasoning behind their “single file model” policy. See more resources about the beauty of copypaste at the end.
An alternative to copypaste is staying on a branch. But I feel like it brings too much overhead in teamwork. Also, I found several more posts about the beauty of copypaste - see more posts in the conclusion.
Maintaining shared research code is hard
Maintenance of heavily used shared code requires a lot of work. Take a look at the torch.nn.Module number of file lines plotted against the Pytorch version. You can see that even the most advanced research teams struggle to keep the complexity in check.
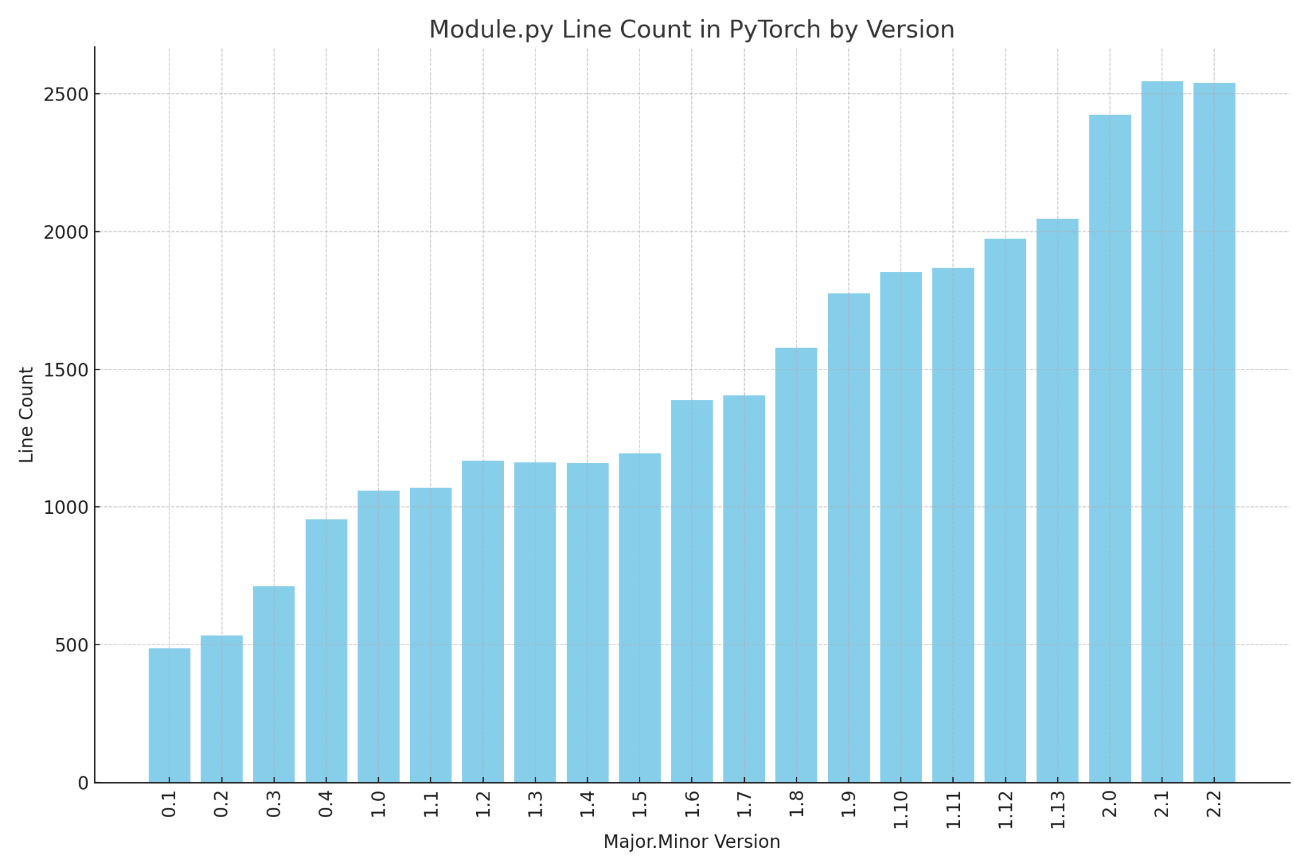
Don’t underestimate time and resources needed to maintain a large shared research code. The more a research library is used the more complicated it becomes. It happens faster than for a typical library because every research direction has a slightly different usecase. Establish very strict rules of what could be contributed back. Otherwise, the shared code becomes fragile and overgrown with a slew of options, buggy optimizations and edgecases. Since the majority of research code dies out, all this extra complexity will never be used again. Dropping some of your shared code will free up some time to do actual research.
Design for exploration, not for code reuse
It is somewhat true that you don’t want to future-proof your code too much even in production. Try to implement the simplest possible solution that meets the requirements. But in production code there are always aspects of maintainability to consider. For example, error handling, speed, logging, modularization is what you typically need to think about.
In research code, none of that matters. You just want to quickly prove that an idea is good or bad in the fastest possible manner and move on. So the dirty simplicity that achieves it without any modules or APIs is totally ok!
Don’t waste valuable time on premature software investments such as:
- creating component interfaces too early in the project. You’ll spend too much time fitting into self-made artificial constraints
- optimizing deep learning training infrastructure before committing to deep learning solution
- using production config/factories/serialization systems or base classes. Quite often you don’t need their functionality during prototyping
- overly-strict linting and type checking systems. No reason to slow down fast-changing throw-away research code.
2. Invest into fast exploration
The goal of a research project is to find a novel solution. No one knows (by definition) what it looks like. It is akin to an optimization process in a complicated research landscape with limited information. To find a good minimum, you need to try many paths, recognize good and bad paths and not get stuck in local minima. To do all of it fast, you sometimes need to make software investments instead of taking tech debt.
Speed up common paths
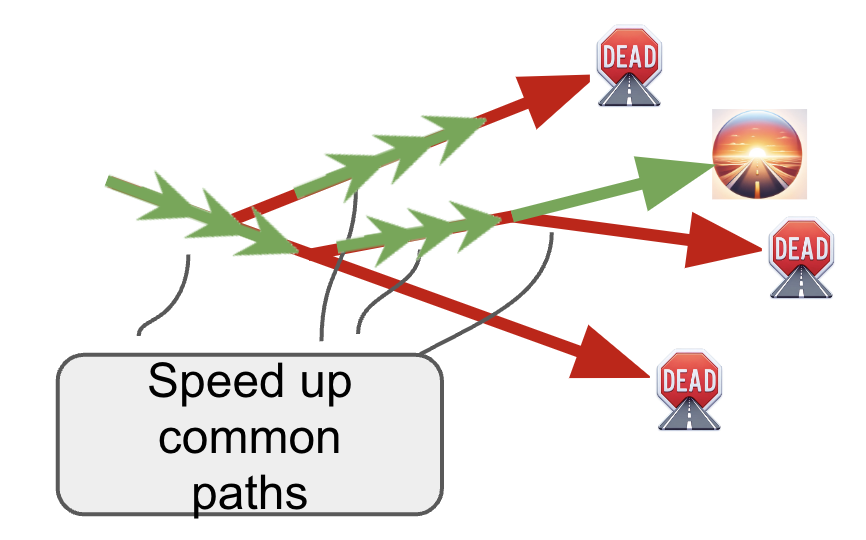
There are several different research paths you want to try. Is there a design, a library or an optimization that would shave off time from the majority of paths? You should be careful to not over-engineer anything because you don’t always know all the ideas you’re about to try. This is very custom to every project, but here are some examples:
- if you train deep networks, invest into training infrastructure. Figure out hyperparameters allowing you to converge during training quickly and reliably
- if every experiment requires you to use a different model, figure out how you can quickly swap them (e.g. by using a simple factory system or just copypaste)
- if every experiment has too many parameters and is hard to manage, invest into a nice configuration library.
Branch out quickly
Researchers should be able to initiate new diverse ideas quickly. It seems easy at the start of the project. But then it gradually becomes harder and harder as people get entrenched in their favourite research paths. To address this, cultural and organizational changes are essential. There should be a process stopping non-promising research before sinking too much money and emotion into it. Regular demo days and technical peer reviews can serve as effective strategies for this purpose. It’s also important to find a balance between people jumping on a new shiny idea and properly closing current projects.
But this is a software post, so here are some practices to make branching out new projects easy:
- keep evaluation code disentangled from algorithms. Evaluations are typically more stable than research directions
- embrace starting a new project from a blank slate, but then watch out which components are reused. Modularizing and cleaning them up is a good investment
- in a new research project, implement the most innovative and risky component first. Doing so identifies the majority of bottlenecks guiding future software design.
Increase signal to noise ratio
Noisy and buggy code makes results so ambiguous and inconclusive that the whole project is going to be a waste of time. While you shouldn’t over engineer things, you can easily follow these simple rules of thumb to avoid messy code:
- avoid code with side-effects
- default to functions rather than classes; and with classes, prefer encapsulation vs. inheritance
- minimize length of functions/classes/modules; minimize number of if-statements
- know python well, but use simple techniques. Resist the temptation going into intellectual weeds of metaclasses, decorators and functional programming.
Software that produces different results during different runs is tricky to work with. If you made an important but wrong decision based on an unlucky seed, you are going to waste a lot of time recovering. Here are some tips when dealing with non-deterministic software:
- understand whether noisy is coming from the algorithm or it’s evaluation. Noise sources compound and you should strive for completely deterministic evaluation.
- don’t stop finding sources of randomness until you really get a reproducible script. Remember that after finding all random seeds, noise might come from data or from generic functions with side-effects.
- vary seeds and determine baseline variance of your results. Don’t take decisions on non-statistically significant results.
Conclusion
The punchline comes from this post about research code: “You don’t bother with [good software design] because the code is not the point. The code is a tool that gets you the answer that you need”.
It is extremely important to have great coding foundations. But at the end of the day, the exploration and actually useful product is what matters. If you use too much production software in research, you waste time needed to discover something new. Instead, find what slows down your exploration process. Speed up research paths by investing in fast branching, time to results and clean noiseless code.
It would be crazy to argue completely against code reuse. I just want to point out that code reuse should be a well-balanced activity. In research, the ratio of throw-away code is larger than in production. The balance is tilted further against reuse. Here are few more great posts with pitfalls of code reuse:
- Reusable Code: The Good, The Bad, and The Ugly
- When It Makes Sense to Repeat Yourself
- Balanced StackExchange with pros and cons of reuse
And here are few more posts arguing for copypasting practices:
- Is copypaste really a problem?
- When Should You Copy-Paste Code?
- The Good and the Bad of Copy-Paste Programming
- “As a senior with 5 YOE, I feel like part of my pay is knowing what code to copy lol”